Research PageRank: Trust Propagation in Bipolar Argumentation Graphs
What if we ranked research claims the way Google ranks web pages?
§1 The problem: claims don't exist in isolation
Scientific knowledge isn't a collection of independent facts. It's a network. "Neural scaling laws predict performance" supports "Larger models are better." The Chinchilla results contradict "Larger models are always compute-optimal." RLHF reward hacking concerns contradict "RLHF effectively aligns models."
When we evaluate the reliability of a claim, we implicitly reason about this network: a claim supported by well-established results is more trustworthy than one contradicted by strong evidence. But doing this manually doesn't scale. In an era of autonomous research generating claims at machine speed, we need algorithmic trust propagation.
PageRank solved an analogous problem for the web: a page linked to by many important pages is itself important. But standard PageRank assumes all links are endorsements. Scientific links are bipolar: they can support or contradict.
§2 Approach: Signed PageRank
The idea is simple. Build a directed graph where:
- Nodes are research claims (e.g., "Scaling laws predict performance")
- Edges are typed as supports (positive trust propagation) or contradicts (negative trust propagation), with optional weights
Then run a modified PageRank:
- Build a signed adjacency matrix where supports edges have positive weight and contradicts edges have negative weight
- Column-normalize so each source distributes equal total influence
- Power iteration with damping:
trust(t+1) = (1-d) * prior + d * A_norm @ trust(t) - Clamp to [0, 1] after each iteration
This builds on bipolar argumentation frameworks (Cayrol & Lagasquie-Schiex, 2005) and is related to TrustRank and BiRank, but keeps the implementation deliberately minimal.
§3 Sample data
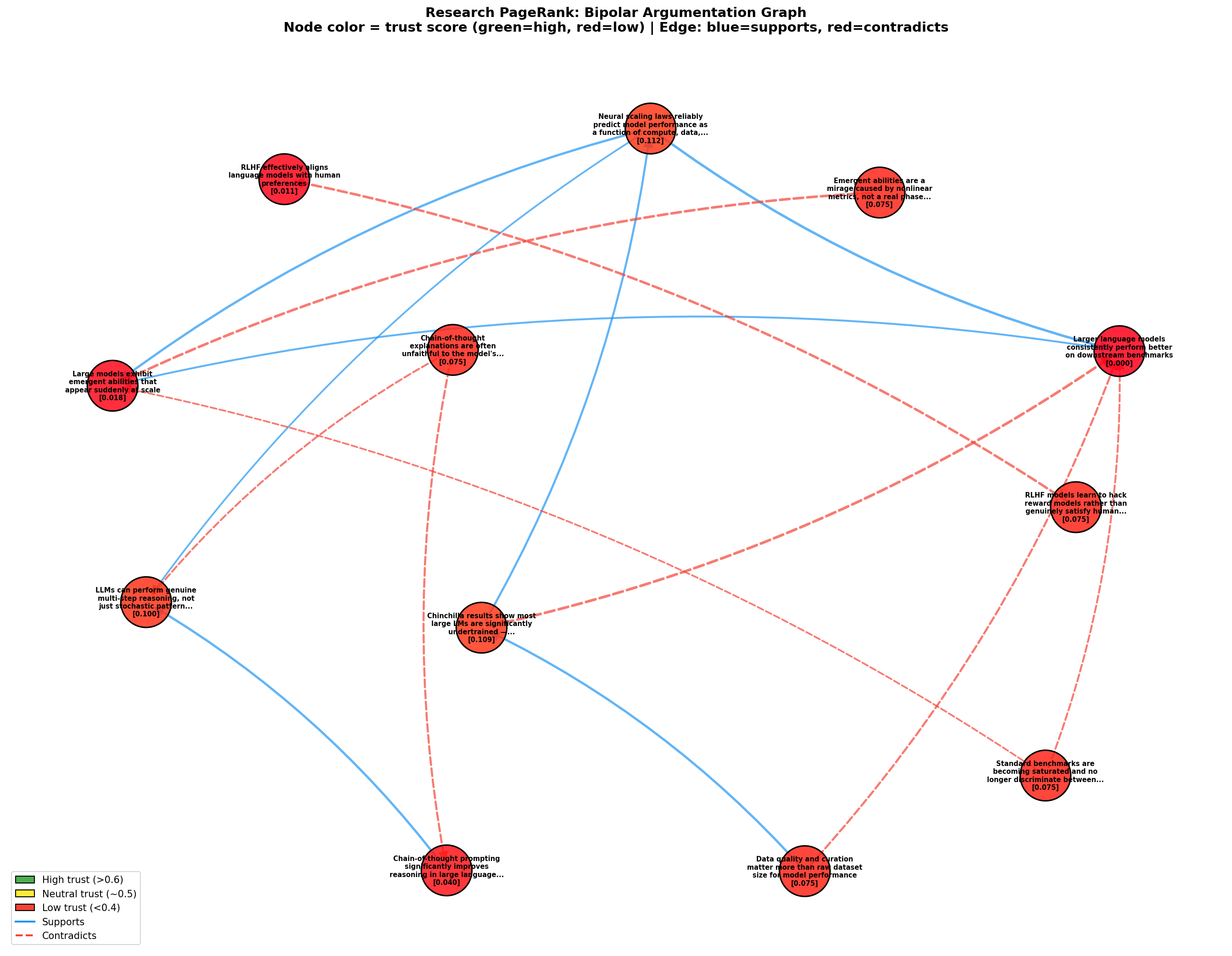
I constructed a graph of 12 claims from real AI research debates, connected by 15 edges (7 supports, 8 contradicts):
- Scaling laws supports bigger is better (weight 0.8)
- Chinchilla contradicts bigger is better (weight 0.9)
- Data quality contradicts bigger is better (weight 0.6)
- Benchmark saturation contradicts bigger is better (weight 0.5)
- Emergent mirage contradicts emergent abilities (weight 0.85)
- Reward hacking contradicts RLHF alignment (weight 0.8)
- ...and 9 more edges
§4 Results
The algorithm converged in 6 iterations. Here's the trust ranking:
| Rank | Claim | Trust Score | Why |
|---|---|---|---|
| 1 | Scaling laws | 0.1122 | Well-supported, no contradictions |
| 2 | Chinchilla | 0.1093 | Supported by data_quality |
| 3 | Reasoning not stochastic | 0.1003 | Net positive support |
| 4-8 | Leaf nodes (mirage, reward hacking, etc.) | 0.0750 | No incoming edges, retain prior |
| 9 | Chain-of-thought | 0.0402 | Supported but also contradicted |
| 10 | Emergent abilities | 0.0180 | 2 supports, 2 contradicts |
| 11 | RLHF alignment | 0.0113 | Only incoming is contradiction |
| 12 | Bigger is better | 0.0000 | 1 support, 3 contradictions |
Intuition check: 4/5 passed.
- PASS: scaling_laws > bigger_better (well-established vs. oversimplified)
- PASS: chinchilla > bigger_better (empirical result vs. contradicted claim)
- PASS: data_quality > bigger_better (quality emphasis vs. scale emphasis)
- FAIL: chain_of_thought > cot_unfaithful (CoT gets penalized; its critic doesn't)
- PASS: rlhf_alignment < rlhf_reward_hacking (disputed vs. critique)
§5 What we learned
What works
Contradiction drainage is the main success. The most-contradicted claim ("bigger is always better") correctly gets its trust drained to zero. Claims with balanced incoming edges get intermediate scores. The topology-driven ranking aligns with intuition in most cases.
What doesn't work
Score compression is the main failure. All scores fall in [0, 0.11], which means the visualization shows everything as red. The combination of negative edge propagation and clamping at zero creates deflationary pressure. A production system would need normalization or a different formulation.
The "unchallenged critic" bias. The one failed intuition check reveals a structural problem: pure critic nodes (like cot_unfaithful) that only contradict others without being contradicted themselves retain their prior trust. In practice, we'd expect a critique that faces no counter-critique to be suspicious, not reliable.
Connection to broader metascience work
This connects to two ongoing threads:
- Research social infrastructure: Trust propagation could feed into automated peer review systems. A claim's trust score reflects the entire epistemic network, not just direct evidence.
- Meta-game architecture: In a contribution-based research platform, Research PageRank could determine "epistemic weight" per contribution, creating incentives for well-supported claims and productive challenges.
Previous experiments in this series explored Bayesian confidence scoring (Epistemic Cascade Validator) and negative result structuring (Negative Result Repository). Research PageRank adds a network-level perspective: claim reliability is not just about local evidence but about position in an argumentation graph.
§6 What would make this real
- Automated graph construction: Use LLMs to extract supports/contradicts relations from paper text
- Evidence weighting: Edge weights from citation counts, methodology quality, sample size
- Dynamic updates: Re-rank when new papers enter the graph
- Ground truth validation: Compare against expert meta-analyses or systematic reviews