Your AI Scientist Is Lying to Itself: Detecting Structural Pathologies in Autonomous Research
47 anomalies. 10 high-severity. All invisible to standard evaluation.
§1 Abstract
We built a structural anomaly detector for AI-generated research and ran it against real outputs from two autonomous research systems. It found 47 anomalies -- 10 of them high-severity -- including confidence inflation (0.98 confidence on a single piece of evidence), unresolved contradictions (claims held active despite majority counter-evidence), and a striking 82% oscillation rate in experiment trajectories. These structural pathologies are invisible to standard evaluation metrics. We argue that autonomous research systems need a dedicated "immune system" layer that monitors the research process itself, not just its outputs.
§2 The problem: why output scores aren't enough
Autonomous AI research systems are proliferating. Tools like AISI's METR, Sakana AI's AI Scientist, and numerous open-source agents now generate hypotheses, design experiments, and draw conclusions with minimal human oversight. The standard quality check is evaluation-layer scoring: an LLM-as-reviewer grades the final paper, or accuracy metrics track experiment performance.
But this misses something fundamental. A research agent can produce outputs that look correct while the underlying research process is structurally unsound. Consider an analogy: a financial auditor doesn't just check whether the balance sheet totals are correct -- they examine the structure of transactions for signs of fraud. Similarly, we need to examine the structure of AI-generated research for pathological patterns.
The question we asked: Can systematic anomaly detection identify failure modes in AI-generated research that evaluation-layer scoring alone misses?
The answer, based on real data from two autonomous research systems, is an emphatic yes.
§3 Method: 7 structural detectors
We built the Research Anomaly Detector (RAD), a tool that ingests the internal state of autonomous research systems and applies seven structural detectors. It examines not the final research output, but the evidence chains, confidence dynamics, contradiction handling, and experiment trajectories that produced it.
| # | Detector | What It Finds | Severity |
|---|---|---|---|
| 1 | Circular Evidence Chains | Claim A depends on B depends on A -- unfalsifiable loops | High/Low |
| 2 | Confidence Score Anomalies | High confidence with sparse or low-fidelity evidence | High |
| 3 | Unresolved Contradictions | Against-evidence exists but claim status unchanged | High/Medium |
| 4 | Uniform Confidence | All claims rubber-stamped at similar confidence levels | High/Medium |
| 5 | Confirmation Bias | Systematic lack of against-evidence across a project | High/Medium |
| 6 | Precision Oscillation | Accuracy oscillating without convergence across experiments | High |
| 7 | Evidence Staleness | All evidence collected on a single date, never revisited | Low |
The data sources were:
- ARA (Autonomous Research Agent): 3 research projects with 35 YAML-structured claims, 178 evidence items, confidence scores, and dependency graphs.
- autoresearch-lite: 21 automated ML experiments with accuracy metrics, keep/discard decisions, and crash records.
§4 Results: 47 anomalies, 10 high-severity
RAD detected 47 structural anomalies across both systems: 10 high-severity, 11 medium, and 26 low.
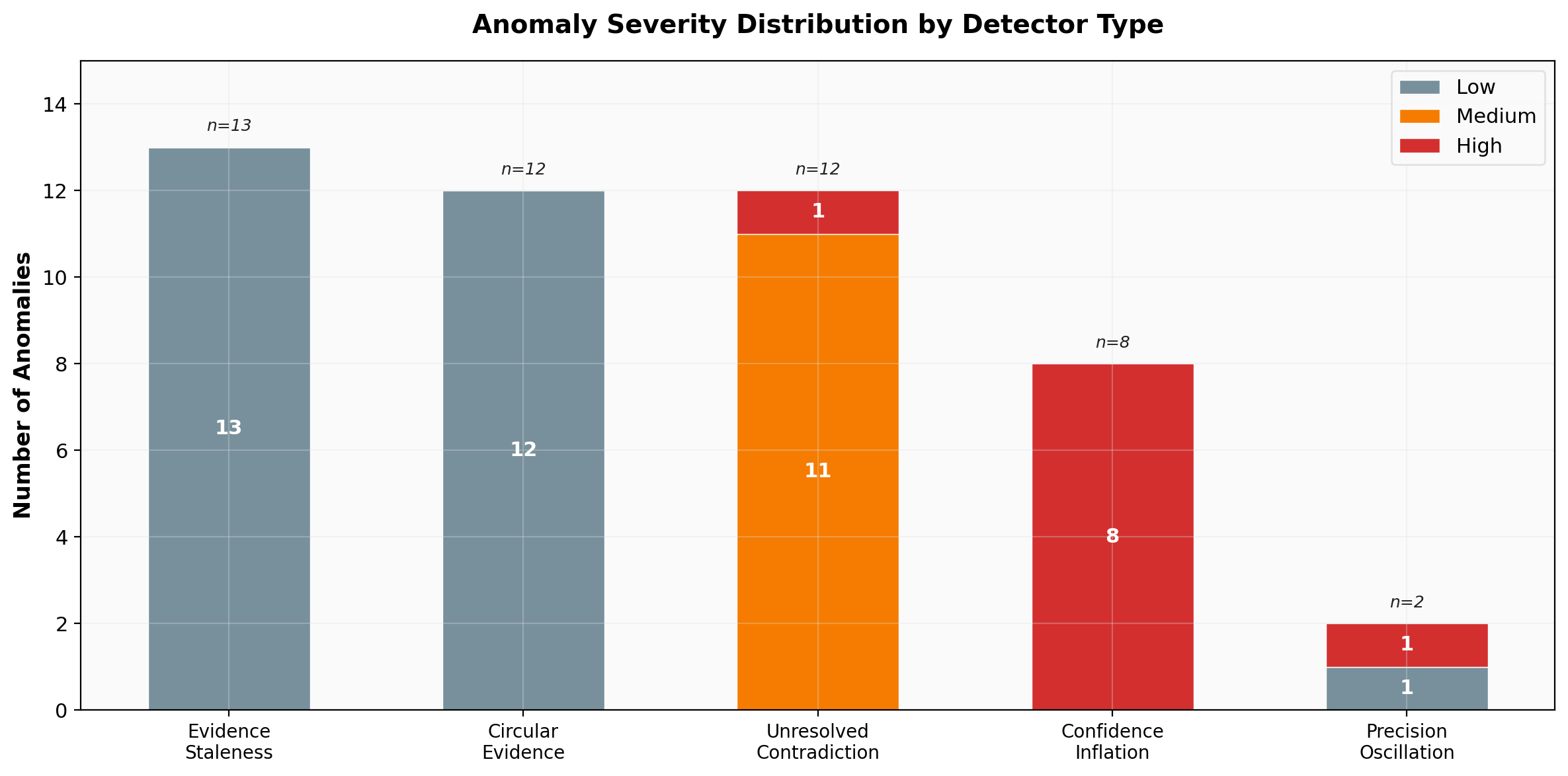
The distribution reveals that while the most numerous anomaly types (evidence staleness and circular evidence) are low-severity, the most dangerous categories -- confidence inflation and unresolved contradictions -- concentrate their anomalies at high and medium severity. This is not a system with minor cosmetic issues; it has structural integrity problems at its core.
The confidence inflation problem
The most alarming finding was systematic confidence inflation in the third ARA project (v2). Eight of its ten claims were flagged for having high confidence scores propped up by minimal evidence.
The worst case: claim-001 carried a 0.98 confidence score based on a single piece of evidence. To put this in human terms, that's equivalent to a scientist saying "I'm 98% certain this is true" after reading one paper and conducting zero experiments.
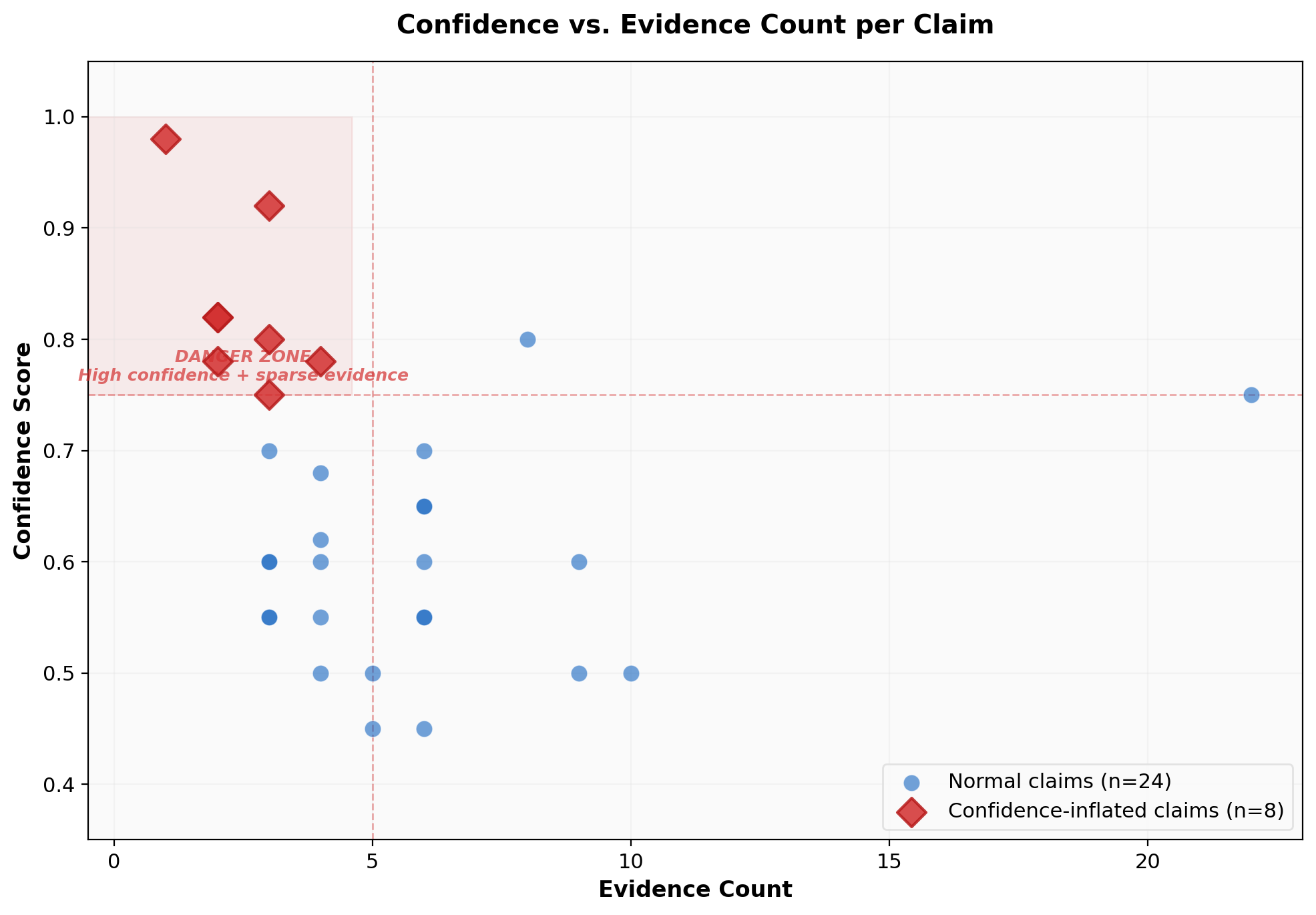
The scatter plot makes the pathology visually obvious. Normal claims (blue dots) cluster in the lower-right quadrant -- moderate confidence supported by substantial evidence. The anomalous claims (red diamonds) cluster in the upper-left "danger zone" -- high confidence with sparse evidence. The pattern is not subtle.
This is particularly dangerous because downstream systems consuming these claims may treat the confidence score at face value. If an autonomous research pipeline uses claim-001's 0.98 confidence to make resource allocation decisions, it's building on sand.
Why does this happen? We hypothesize that LLM-based research agents inherit the tendency of their base models to produce calibration-inflated outputs. When an LLM generates a confidence score, it's performing a kind of introspection that language models are notoriously poor at. The agent "feels" confident because it can generate fluent, coherent reasoning -- but fluency is not evidence.
The precision oscillation problem
The autoresearch-lite system exhibited a different but equally concerning pathology: 82% of consecutive experiment pairs changed direction in accuracy, indicating that the system was oscillating rather than converging.
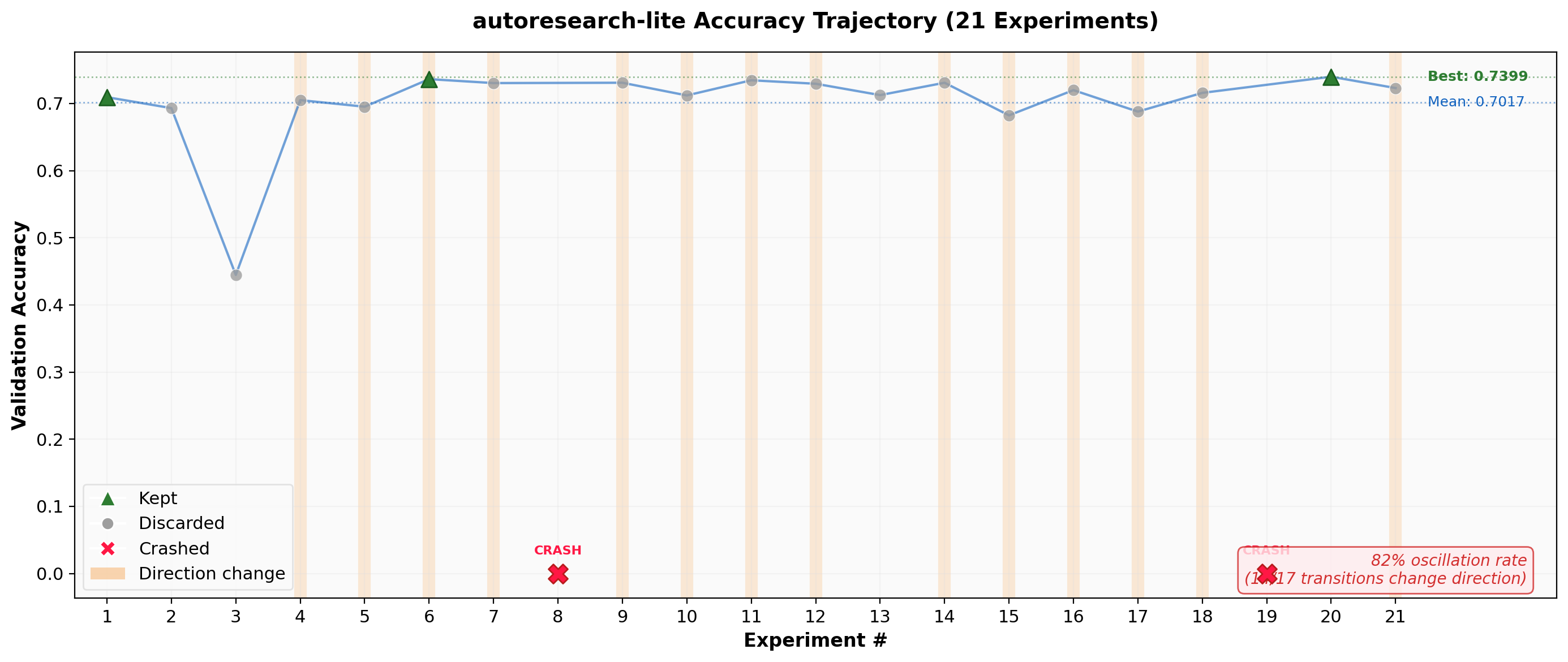
Out of 21 experiments, only 3 were "kept" (green triangles) as improvements. The trajectory shows the system bouncing between the 0.68-0.74 accuracy range with no clear convergent trend. Two experiments crashed entirely (red X marks). The orange bands highlight the pervasive direction changes -- 14 out of 17 valid transitions reversed the previous trend.
This oscillation pattern tells us something important: the LLM driving experiment design lacks a coherent search strategy. It tries increasing the learning rate, then decreasing it. It adds regularization, then removes it. Each experiment is locally reasonable, but the sequence reveals no systematic exploration of the parameter space.
The keep rate of 3/19 valid experiments (16%) means the system is operating at roughly 5x the computational cost of a human ML practitioner who would use the oscillation signal to narrow their search.
Unresolved contradictions: the zombie claims
Twelve claims across the ARA projects were flagged for having substantial counter-evidence (40-67% of total evidence arguing against the claim) while remaining in "active" status with unchanged confidence scores.
The most egregious case: claim-004 in the automated-research-methodology project had 2 out of 3 evidence items arguing against it (67%), yet remained active with 0.60 confidence. In any human research context, a claim with a 2:1 ratio of counter-evidence would be either revised, weakened, or killed.
This reveals a structural failure in how the research agent handles disconfirming information. It collects against-evidence dutifully -- suggesting the evidence-gathering process works -- but then fails to update its beliefs accordingly. The agent exhibits what we might call epistemic inertia: the tendency to maintain initial conclusions regardless of subsequent evidence.
§5 The full picture
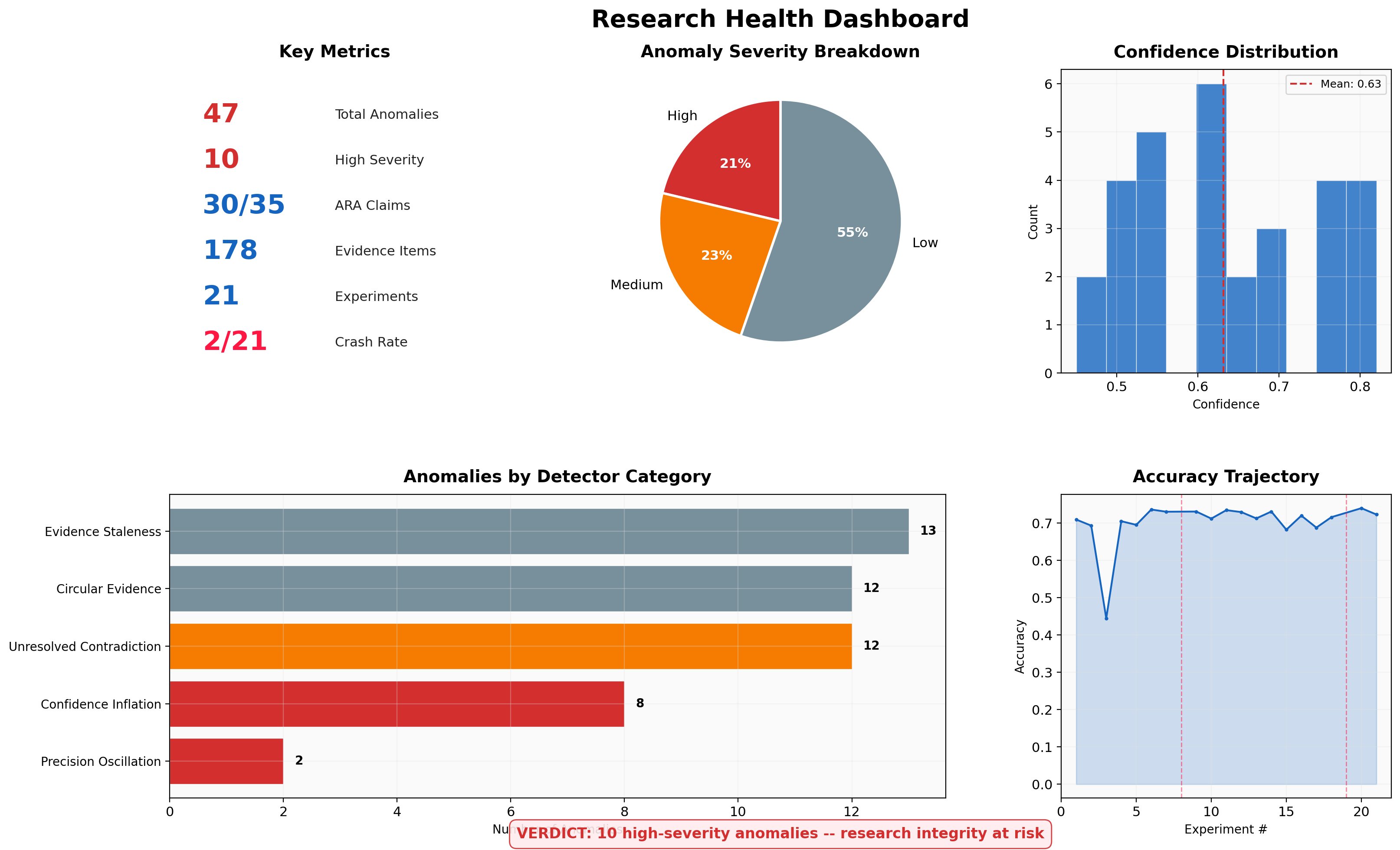
The dashboard summarizes the overall health of the research corpus. Key observations:
- Confidence distribution is bimodal, with a cluster around 0.50-0.65 (the "hedging" range) and a secondary cluster above 0.75 (the "inflation" range). A healthy confidence distribution should reflect the actual heterogeneity of evidence quality.
- Evidence staleness is pervasive: 13 claims have all evidence collected on the same date. Research claims should be tested and re-examined over time, not assembled in a single burst.
- Circular evidence chains (12 instances) indicate that the claim dependency graph has structural loops. While the detected cases are mutual references (low severity), they signal that the system's knowledge graph may be less independent than it appears.
§6 Implications for autonomous research systems
These findings have three practical implications:
1. Structural monitoring should be a first-class component. Just as software systems have observability stacks (metrics, logs, traces), autonomous research systems need structural health monitoring. RAD-style detectors should run continuously, not as post-hoc audits.
2. Confidence calibration needs external grounding. LLM-generated confidence scores are unreliable without external calibration mechanisms. Possible approaches include: requiring minimum evidence thresholds before allowing high confidence, using ensemble disagreement as a calibration signal, or enforcing Bayesian updating rules that bound confidence changes relative to evidence quantity.
3. Search strategy needs meta-level reasoning. The oscillation pattern in autoresearch-lite suggests that experiment-level LLM reasoning is insufficient for effective search. The system needs a meta-level component that tracks the trajectory of experiments and adjusts strategy accordingly -- for example, detecting oscillation and switching to a grid search or Bayesian optimization approach.
§7 Limitations and next steps
Limitations
- RAD currently operates on static snapshots rather than streaming data. Real-time detection would catch anomalies as they emerge.
- The detector thresholds (e.g., confidence > 0.75 with < 5 evidence items) are hand-tuned. A learned threshold model could adapt to different research domains.
- We tested against only two autonomous research systems. The detector types are informed by these systems' architectures and may miss pathologies in differently structured agents.
- The "uniform confidence" and "confirmation bias" detectors did not trigger on this dataset, suggesting either that these systems avoid those particular pathologies or that the detectors need tuning.
Next steps
- Temporal analysis: Ingest version-controlled claim histories to detect confidence drift over time, not just snapshot anomalies.
- Cross-system benchmarking: Run RAD against other autonomous research systems (AI Scientist, AISI agents) to build a taxonomy of common structural pathologies.
- Automated remediation: Instead of just detecting anomalies, propose specific fixes -- e.g., "reduce confidence to 0.45 given evidence count" or "flag claim for re-examination."
- Integration as a CI check: Run RAD as part of the autonomous research pipeline, blocking claims from advancing when structural anomalies are detected.
Code: github.com/t46/metascience-experiments/tree/main/research-anomaly-detector
This experiment is part of the Metascience Experiments project, which applies the scientific method to the practice of AI-assisted research itself. The Research Anomaly Detector is open source.
Built by Shiro Takagi / Unktok. April 2026.