Building Infrastructure for Autonomous Research: Three Experiments
When AI runs 100 experiments a night, what breaks?
§1 The autoresearch era is here
We have entered the era of autonomous research. Andrej Karpathy's autoresearch project demonstrated a simple but powerful idea: give an LLM a research question, let it write and run experiments, and log the results — all night, every night. People are already reporting running 100+ experiments per night on a single H100, with a keep rate of about 15%.
Sakana AI's AI Scientist v2 showed that LLM-driven research can produce papers with novel contributions, though 42% of runs still fail due to coding errors. The message is clear: autonomous research systems are productive, but noisy.
And here lies the problem. The current infrastructure for managing autoresearch output is essentially flat logging — TSV files, JSON lines, or simple databases where every result is stored equally. This works when a human reviews 10 results. It does not work when the pipeline generates 100 results per night and the outputs of one experiment become the inputs to the next.
I believe that autoresearch needs its own infrastructure layer — systems that handle curation, quality assurance, and knowledge representation at machine speed. To explore this, I built three open-source prototypes, each addressing a different failure mode. I then validated all three against real autoresearch output.
§2 Three failure modes, three experiments
When you scale autonomous research, three things break:
- Curation: Good results are buried alongside failures in flat logs. There is no mechanism for good configurations to propagate or build on each other.
- Reliability: A false positive — an experiment that "succeeds" but doesn't reproduce — can poison every downstream experiment that treats it as a premise. At machine speed, this cascade contamination unfolds in hours.
- Knowledge transfer: When AI agents are both the producers and consumers of research, routing knowledge through human-readable papers (PDFs, PNG figures) is a lossy bottleneck.
Each experiment targets one of these failure modes.
§3 Validation: Building a real autoresearch pipeline
Before diving into each prototype, a note on methodology. It would be easy to build these tools and test them only on synthetic data. I did that first — and then realized that claiming to build "autoresearch infrastructure" without testing against actual autoresearch output is not credible.
So I built autoresearch-lite, a lightweight autoresearch loop that follows Karpathy's design: an LLM proposes modifications to a training script, the script runs, results are logged, and improvements are kept while regressions are discarded. The task is CIFAR-10 image classification with a CNN, running on an Apple Silicon MacBook Pro (M3 Max).
The loop ran 21 experiments autonomously. An LLM proposed hyperparameter changes (learning rate, optimizer, architecture, regularization), each experiment trained for up to 60 seconds, and the system logged results in a Karpathy-compatible results.tsv:
- 3 kept (improved accuracy): baseline, increased epochs, reduced weight decay
- 16 discarded (no improvement): LR tuning, architecture changes, augmentation tweaks
- 2 crashed: a failed residual connection attempt and an LLM parsing error
Validation accuracy improved from 0.709 (baseline) to 0.740 (best). This is a real autoresearch session — real gradients, real loss curves, real GPU memory — and the output is what all three prototypes were validated against.
§4 Evolutionary Experiment Database: Selection at scale
Problem: Flat experiment logs treat every result equally. A brilliant configuration and a random failure occupy the same row in a TSV.
Approach: Treat each experiment result as an individual in an evolutionary population. Define a fitness function over result quality, reproducibility, novelty, and efficiency. Apply tournament selection, crossover, and mutation to propagate good configurations and explore their neighborhood.
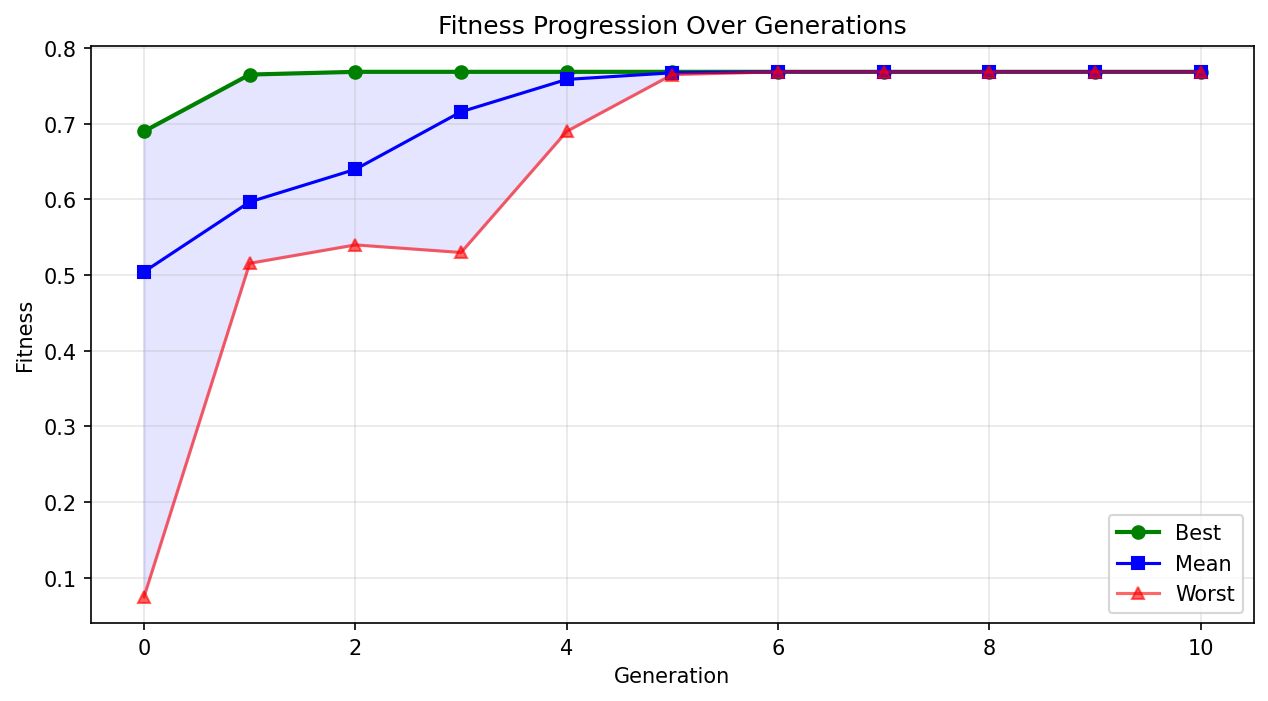
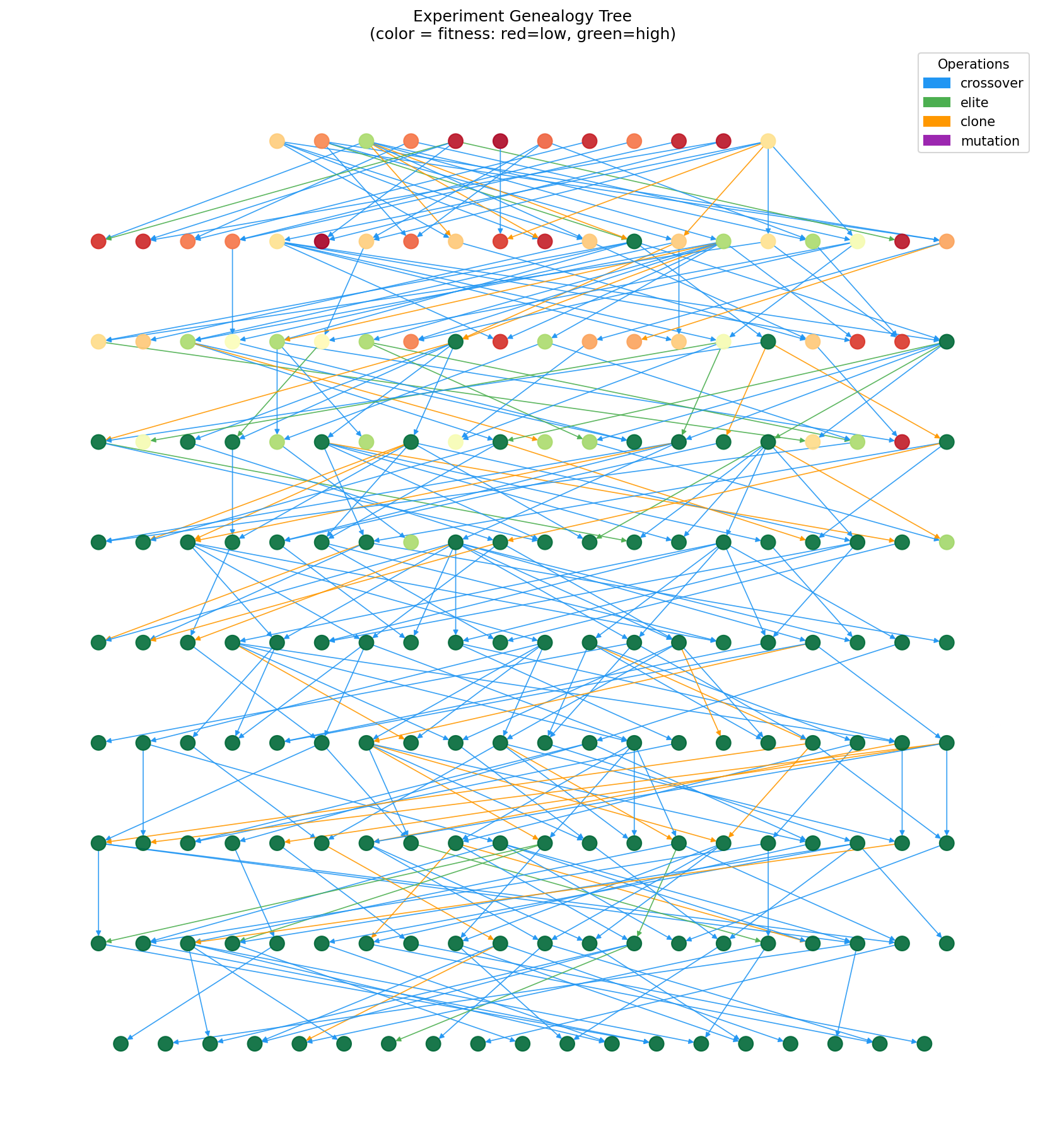
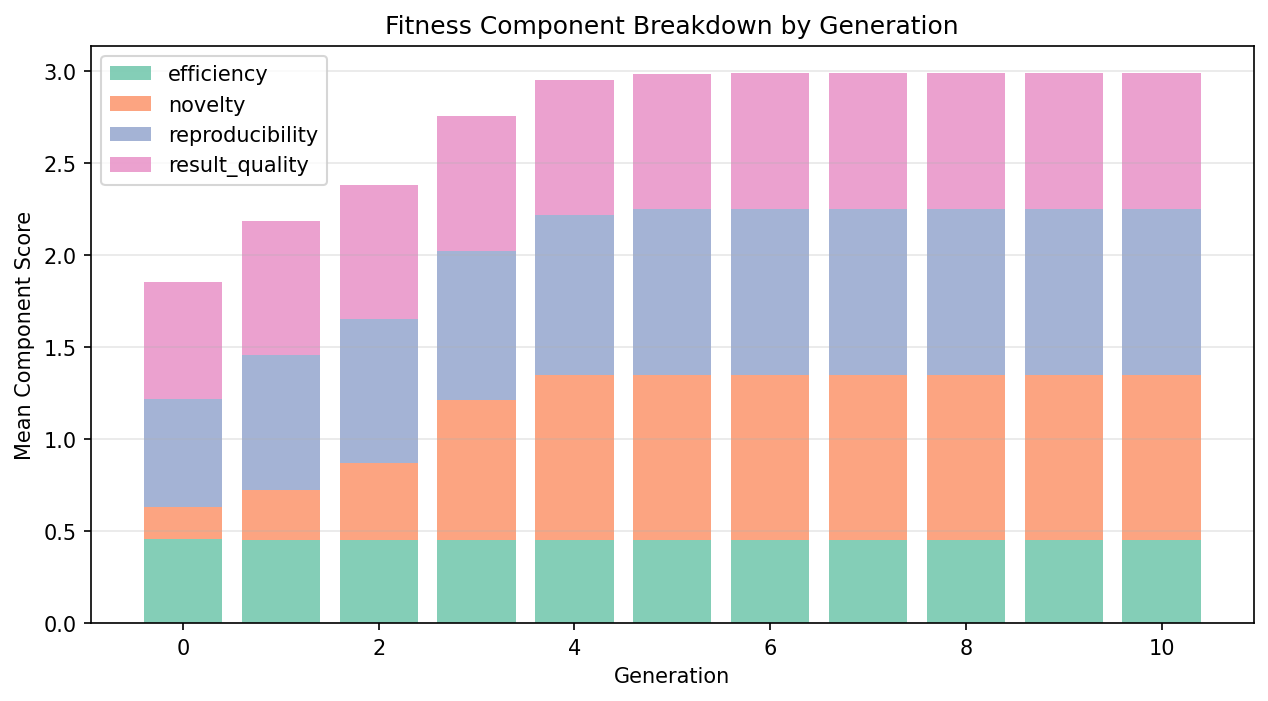
Validation result: When fed the 21 autoresearch experiments, the fitness function correctly separated outcomes: keep experiments scored 0.62, discards 0.57, and crashes 0.10. Over 10 generations of evolution, fitness improved by 9.4%. Critically, crossover operated on actual hyperparameters — combining the learning rate from one experiment with the weight decay from another — which is a standard and meaningful hyperparameter search strategy. The system even "rediscovered" weight_decay=5e-5, the value that produced the best real result.
Limitation: Evolution operated on numeric hyperparameters but could not mutate categorical choices (optimizer type, activation function). Population diversity collapsed by generation 7 due to small population size (21 individuals). Most importantly, the system generates new hyperparameter configurations but has no pipeline to actually run them — it can propose but not verify.
Metascience insight: Evolutionary selection is a natural fit for hyperparameter-level autoresearch. But for higher-level research — evolving hypotheses, not just hyperparameters — the genetic operators need to work at the semantic level, requiring LLM integration for crossover and mutation.
§5 Epistemic Cascade Validator: Breaking the contamination chain
Problem: In an experiment chain A → B → C, if A produces a false positive, B and C build on a false premise. In traditional science, peer review catches this one paper at a time. In autoresearch, 100 experiments per night makes human review impossible.
Approach: Assign each experiment result a Bayesian confidence score computed from reproduction rate (40%), statistical evidence (25%), effect size (20%), and code quality (15%). A decision engine gates results below a confidence threshold, preventing low-confidence outputs from becoming downstream premises.
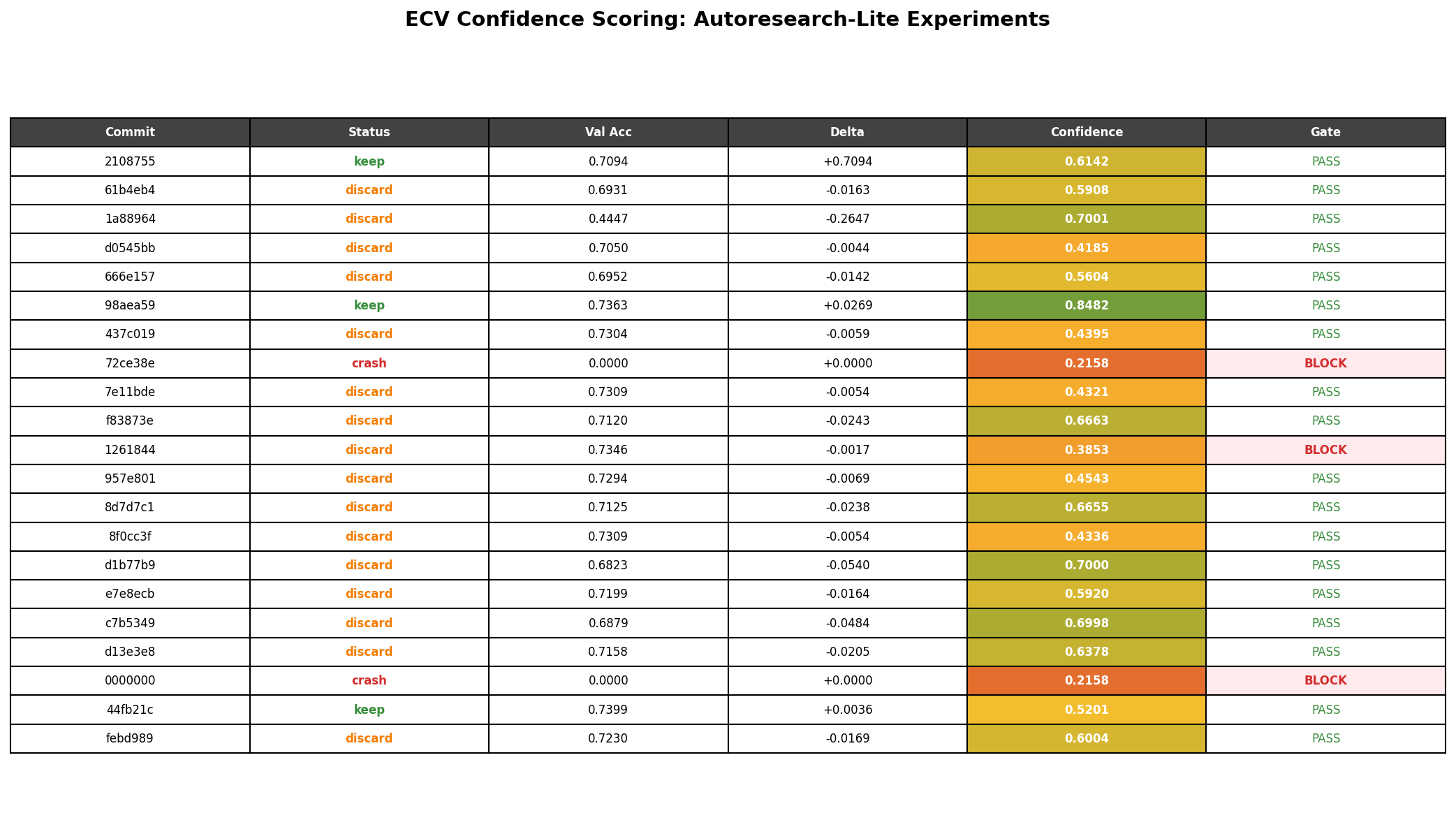
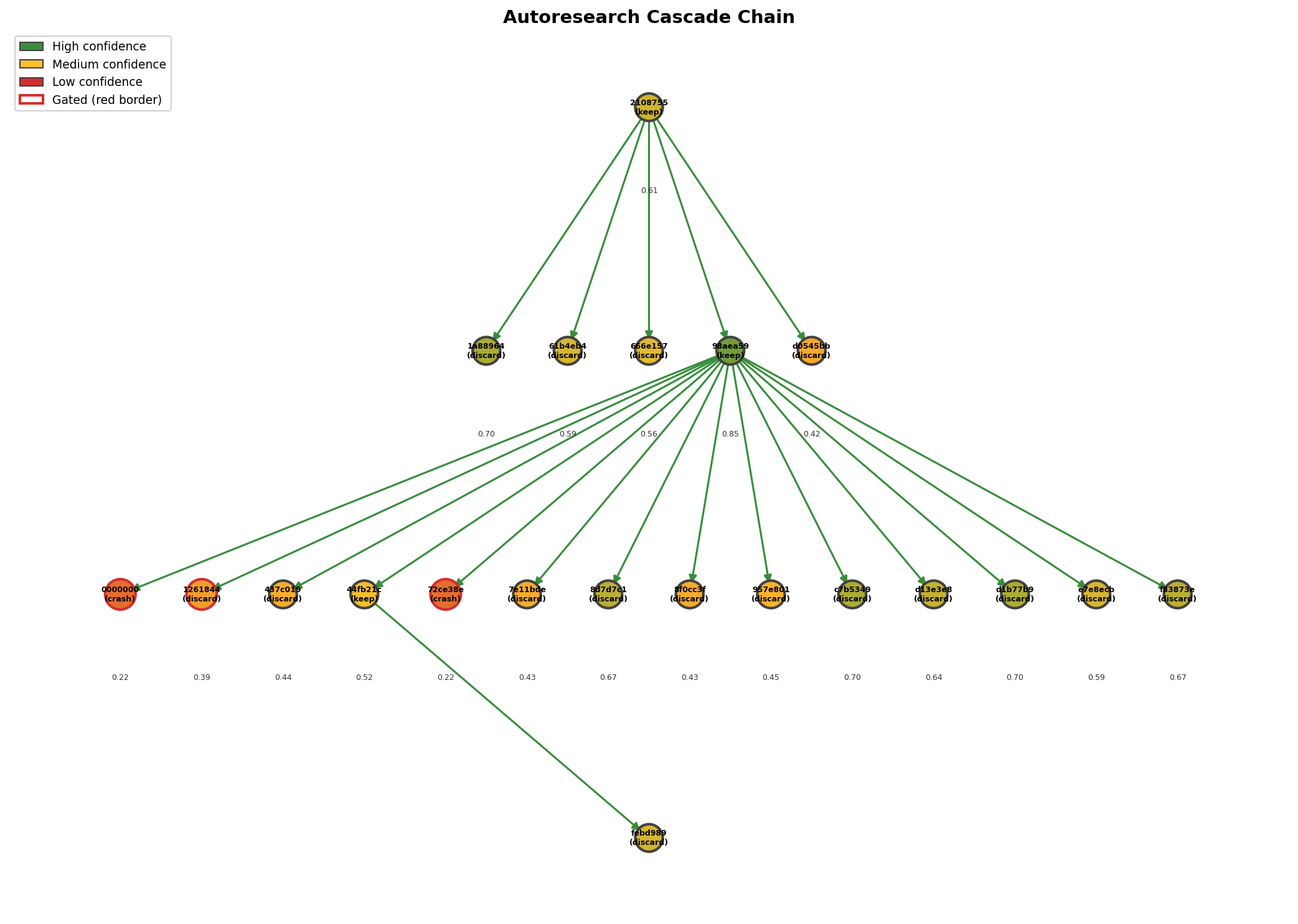
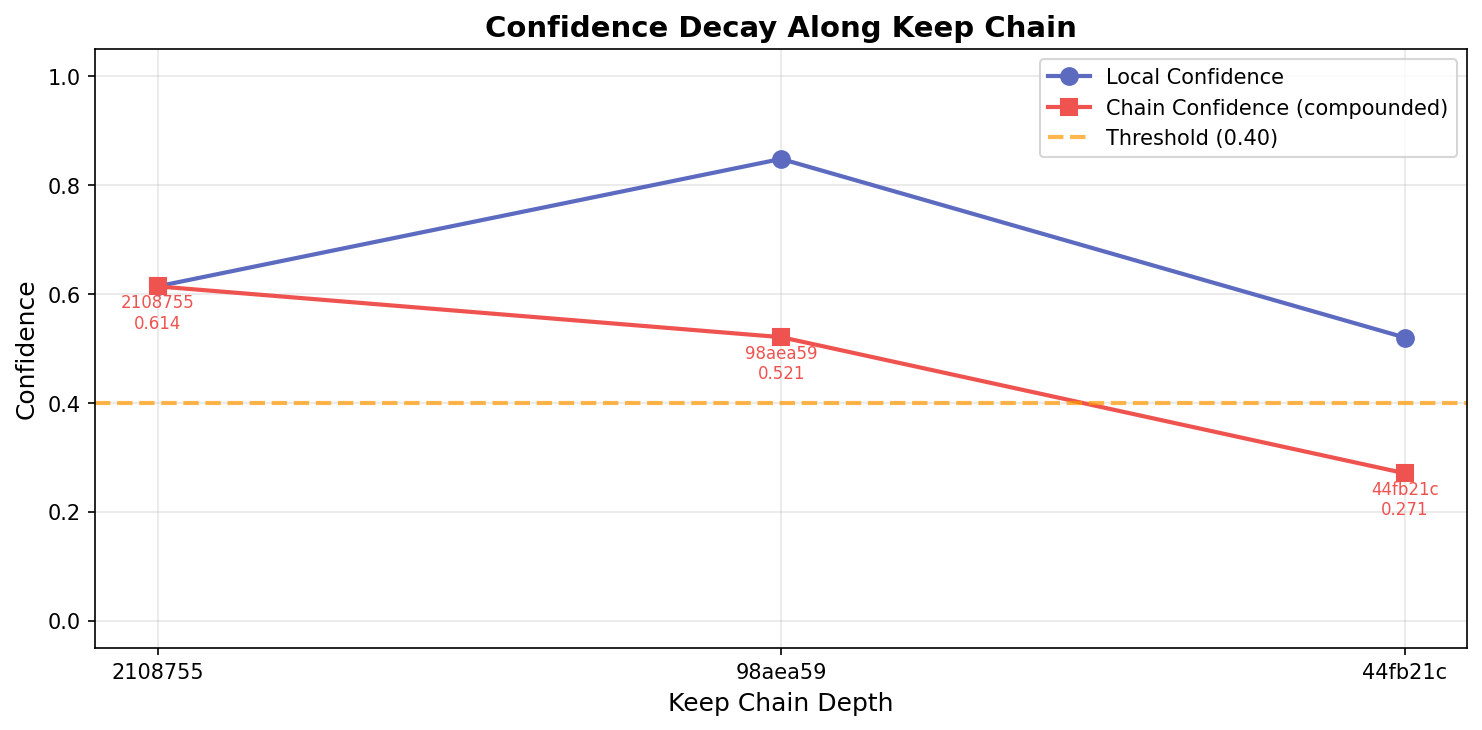
Validation result: Against the 21 autoresearch experiments, the system correctly ordered confidence scores: keep (0.66) > discard (0.56) > crash (0.22). Both crashes were correctly gated (100% crash detection). In the cascade analysis, the 3-node keep chain (baseline → epochs increase → weight decay reduction) showed confidence compounding from 0.61 down to 0.27 — correctly flagging that accumulated uncertainty makes downstream results less trustworthy.
Limitation: The separation between keep and discard was not statistically significant (p=0.42, only 3 keeps). The effect size mapping is direction-agnostic: a large accuracy drop gets a high effect size score, inflating discard confidence. With N=21, the validation shows the system runs on real data and produces reasonable orderings, but cannot establish statistical calibration.
Metascience insight: The reproducibility crisis plays out at machine speed in autoresearch. Confidence scoring is a viable mechanism, but it needs to be direction-aware and validated at scale (hundreds of experiments). The cascade compounding result is particularly interesting: even a chain of three "good" experiments accumulates enough uncertainty to cross below the gating threshold, suggesting that autoresearch pipelines may need periodic "re-anchoring" through independent reproduction.
§6 LLM-Native Research Artifacts: Knowledge for machines
Problem: Scientific knowledge is packaged for human consumption: natural language papers, visual figures, implicit assumptions. When AI agents are the primary readers, this format is a bottleneck. Research by AgentRxiv showed that machine-optimized formats improve AI performance by 13.7% on reasoning benchmarks.
Approach: Define structured artifact schemas (Pydantic v2 models) where uncertainty, conditions, causation, and provenance are first-class citizens — not sentences buried in section 4.3 of a PDF. Build an agent interface with three operations: query() for structured Q&A, compose() for cross-artifact synthesis, and diff() for contradiction detection.
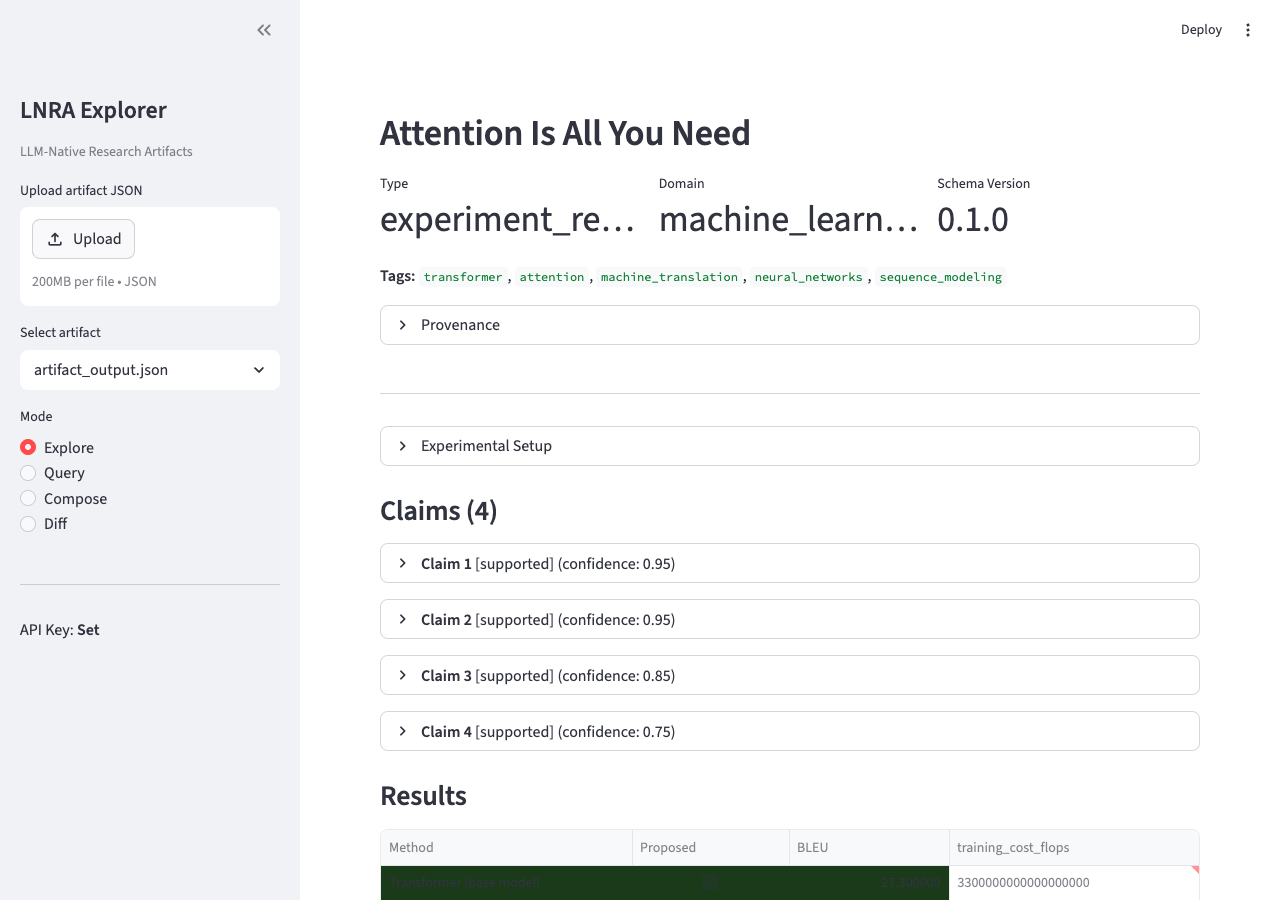
Validation result: The entire autoresearch session (results.tsv + train.py + git log) was converted into a structured artifact. All 5 research queries returned correct answers: the system identified that increasing epochs was the most impactful change (+2.69%), correctly diagnosed both crash causes, and detected the diminishing-returns pattern in late experiments. compose() with an existing Attention Is All You Need artifact surfaced novel insights about how iterative optimization and architectural innovation are complementary strategies. diff() correctly found zero method overlap and identified methodology differences.
Limitation: Autoresearch output required reshaping into a "pseudo-paper" format before the converter could process it — no native TSV/log ingestion. The resulting artifact was quantitatively sparser than artifacts from real papers (fewer precise metrics, no confidence intervals). The entire 21-experiment session compressed into a single artifact, losing per-experiment granularity.
Metascience insight: The most valuable operation for autoresearch turned out to be compose(), not query(). Individual experiment results are easy to log; what's hard is synthesizing patterns across many experiments. The cross-artifact synthesis — finding that "critique calibration is the key differentiator" or that "d-separation explains ablation gaps" — surfaced insights not visible in any individual experiment. This suggests that the primary value of structured knowledge representations in autoresearch is aggregation, not retrieval.
§7 How the three connect
These experiments are complementary layers of the same stack:
- Individual level: The Evolutionary Experiment Database selects and propagates good experiments within a population.
- Chain level: The Epistemic Cascade Validator prevents unreliable results from corrupting downstream work.
- Knowledge level: LLM-Native Research Artifacts ensure that when results do propagate, they carry structured uncertainty, conditions, and provenance that downstream agents can reason about.
Together, they sketch an infrastructure layer for autonomous research that goes beyond "run experiments and log results." The goal is a system where quality emerges from the structure itself — where good results are amplified, bad results are contained, and knowledge flows in formats that machines can actually use.
§8 Metascience reflections
Building and validating these prototypes surfaced several insights that I did not anticipate:
The infrastructure gap is real, but the shape is surprising. I expected the main challenge to be algorithmic — designing better scoring functions or smarter evolutionary operators. Instead, the hardest part was the adapter layer: mapping the messy, heterogeneous output of real autoresearch systems into structured formats. Every data source had a different shape. This suggests that the first and most impactful infrastructure investment for autoresearch is not a better algorithm but a standard output format.
Small N is the enemy. With 21 experiments, statistical claims are fragile. The ECV's keep-vs-discard separation was not significant. The EED's population diversity collapsed in 7 generations. Many of the "limitations" in these prototypes are actually just "need more data." This is both good news (the tools may work fine at scale) and a methodological warning (validating autoresearch infrastructure requires autoresearch at scale).
The semantic gap. The EED revealed a fundamental tension: evolutionary operators work on numeric vectors, but research experiments are structured objects where meaning lives in the text. "Crossing learning rate from experiment A with weight decay from experiment B" is meaningful. "Crossing hypothesis A with hypothesis B" requires understanding what a hypothesis means. The gap between hyperparameter optimization (well-suited for evolution) and hypothesis evolution (requires semantic understanding) is the frontier.
Aggregation over retrieval. LNRA's most valuable operation was not query() (answering questions about one experiment) but compose() (synthesizing patterns across many). This suggests that as autoresearch scales, the bottleneck shifts from "finding results" to "understanding what the results collectively mean." The infrastructure layer needs to support not just storage and retrieval, but synthesis.
Honest validation matters. The first version of these tools was tested only on synthetic data. The second was tested against our own research automation tools, which we initially framed as "autoresearch validation" — but it wasn't, because none of those tools actually ran ML experiments. Only after building autoresearch-lite and running real experiments could we make honest claims. This experience reinforces a core metascience principle: the credibility of infrastructure depends on the credibility of its validation.
§9 What's next
These are prototypes with honest limitations, not production systems. Each one tests a specific hypothesis:
- That evolutionary selection is a better curation mechanism than flat logging for autonomous research. Supported at the hyperparameter level; open question at the hypothesis level.
- That Bayesian confidence scoring can prevent cascade contamination without human review. Crash detection works; keep/discard separation needs more data and direction-aware scoring.
- That machine-native knowledge representations outperform human-readable formats for AI-to-AI communication. Compose() is the killer feature; native log ingestion is needed.
Next steps include scaling to hundreds of experiments, integrating the tools with live autoresearch pipelines, and developing LLM-based genetic operators for semantic-level evolution. I plan to continue releasing experiments like these — open-source prototypes that explore what research infrastructure should look like when AI does the research.
If you're working on similar problems, I'd love to hear from you. All code is open source:
- autoresearch-lite — lightweight Karpathy-compatible autoresearch loop for Apple Silicon
- evolutionary-experiment-database — evolutionary selection and genealogy tracking for experiment results
- epistemic-cascade-validator — Bayesian confidence scoring and cascade contamination prevention
- llm-native-research-artifacts — structured knowledge representations for AI-to-AI research communication